

ローカルLLMの安全性と安心運用
中小企業にとってAI導入で最も懸念されるのは「情報漏洩」や「外部依存のリスク」です。ローカルLLMを導入することで、外部クラウドに頼らず、自社サーバー内でデータを完結させることが可能になります。これにより、機密情報を安全に活用しつつ、生産性を高められます。本項目では、データセキュリティ、法令遵守、業界別リスク対策について詳しく解説し、安心してLLMを活用できる環境づくりをご提案します。
自社特化学習の重要性
汎用的なAIでは、各社独自の業務文脈や専門用語に対応できず、誤った回答や曖昧な提案になりがちです。自社の規程、マニュアル、過去のナレッジを学習させることで、初めて「自社専用の相談役」として機能するようになります。本項目では、自社特化学習の導入メリットや導入事例、データ準備の進め方などを整理し、限られた投資で大きな成果を生み出す仕組みを解説します。

RAG(検索拡張生成)による最新情報活用
RAG(Retrieval Augmented Generation)は、外部文書や社内データベースから必要な情報を取り出し、それをAIに組み込んで回答を生成する仕組みです。これにより、膨大な文書の中から最新かつ正確な回答を瞬時に提示できます。本項目では、RAGの仕組み、適用シーン(規程検索・商品情報回答・顧客対応)、導入のステップ、効果的なデータ準備方法についてわかりやすく解説します。

ファインチューニング手法とその活用
RAGと並ぶ強力な方法が「ファインチューニング」です。これはベースとなるLLMを、自社の専門データで再訓練し、AIの基本性能そのものを高める手法です。業界特有の応答品質を担保できる一方で、コストやデータ量の見積りが重要です。本項目では、ファインチューニングの種類(フル、LoRA、QLoRA)、導入判断の基準、中小企業でも実現可能なスモールスタート手法を詳しく紹介します。
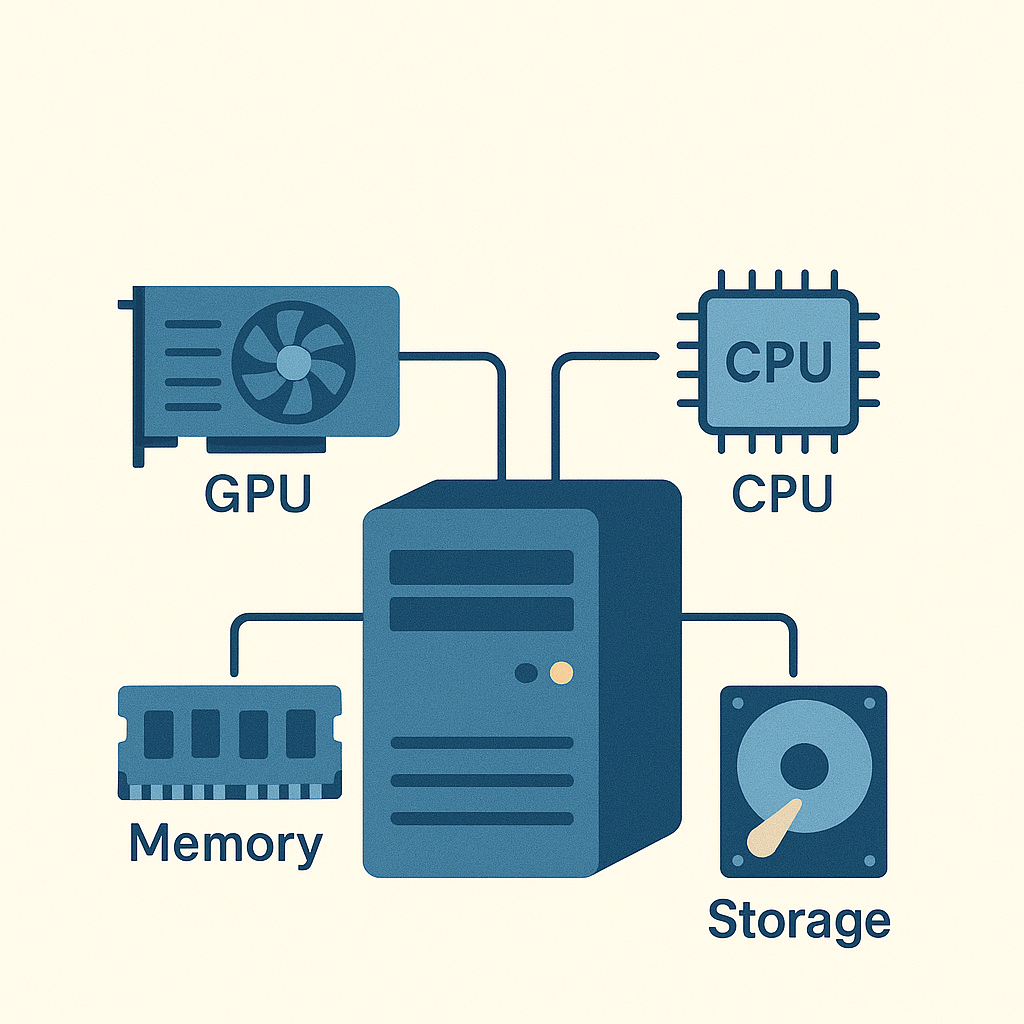
必要なハードウェアと運用設計
ローカルLLMの運用にあたり、最も現実的な課題が「ハードウェア要件」です。GPU性能やメモリ容量、電力消費などを適切に設計することで、コストと性能の最適バランスを確保できます。本項目では、中小企業でも導入しやすい構成例(RTXクラスGPU+ワークステーション)から、本格的サーバー環境まで、予算に応じた推奨環境と導入手順をわかりやすく整理します。
導入・運用サポートと導入後の価値最大化
AIは「導入して終わり」ではなく、運用と改善を繰り返すことで初めて成果が出ます。当サービスでは、初期設計からデータ整理、学習、運用サポートまでワンストップで提供します。さらに、導入後も継続的に効果測定を行い、業務フロー改善や追加学習を支援。中小企業がAIを“業務の一部”として根付かせるための総合的パートナーシップをご提案します。